筆者剛好在 YouTube 上看到 跟李沐学AI - 肝了6个月的AudioLLM,开源了【100亿模型计划】 的影片,裡面提到 Boson AI 開源了一個叫做 higgs-audio 的 AudioLLM 模型,筆者看了一下 GitHub 的介紹,覺得概念還不錯(不難懂),所以就寫了一篇文章來介紹這個模型背後的運作概念。
在開始之前,先要有一個基本概念,對於電腦而言,不論是「聲音」或是「文字」對它都是一樣的東西(數字)。如果直接把聲音當作另一個語言來訓練是否可行?
Higgs-Audio 使用了許多現成的概念與工具(音訊編解碼、資料處理等),先逐一介紹,後續就會知道這些工具的作用
# requirements.txt
descript-audio-codec
torch
transformers>=4.45.1,<4.47.0
librosa
dacite
boto3==1.35.36
s3fs
torchvision
torchaudio
json_repair
pandas
pydantic
vector_quantize_pytorch
loguru
pydub
ruff==0.12.2
omegaconf
click
langid
jieba
accelerate>=0.26.0
將音訊壓縮成低比特率的離散 codes(如約 8 kbps 等),再由 codes 解碼重建音訊波形,輸入音訊可為 44.1/48 kHz 等取樣率
音訊分析的套件,可用來做「數位訊號處理」
跟文字的 Tokenizer 功能類似,目的是將連續的聲音轉換成離散的 ID
- 文字 Tokenization:文字 $\rightarrow$ 離散 token ID
- 語音 Vector Quantization:連續向量 $\rightarrow$ 離散 codebook ID
處理音訊檔案的工具,可以做切割、拼接、轉換格式、音量調整等等 ...
文字語言辨識工具,用於判斷文字是哪種語言
vector_quantize_pytorch)把連續的聲音轉換成有限離散的 tokendescript-audio-codec)把生成的音訊 tokens 還原成聲音,模型就能開口說話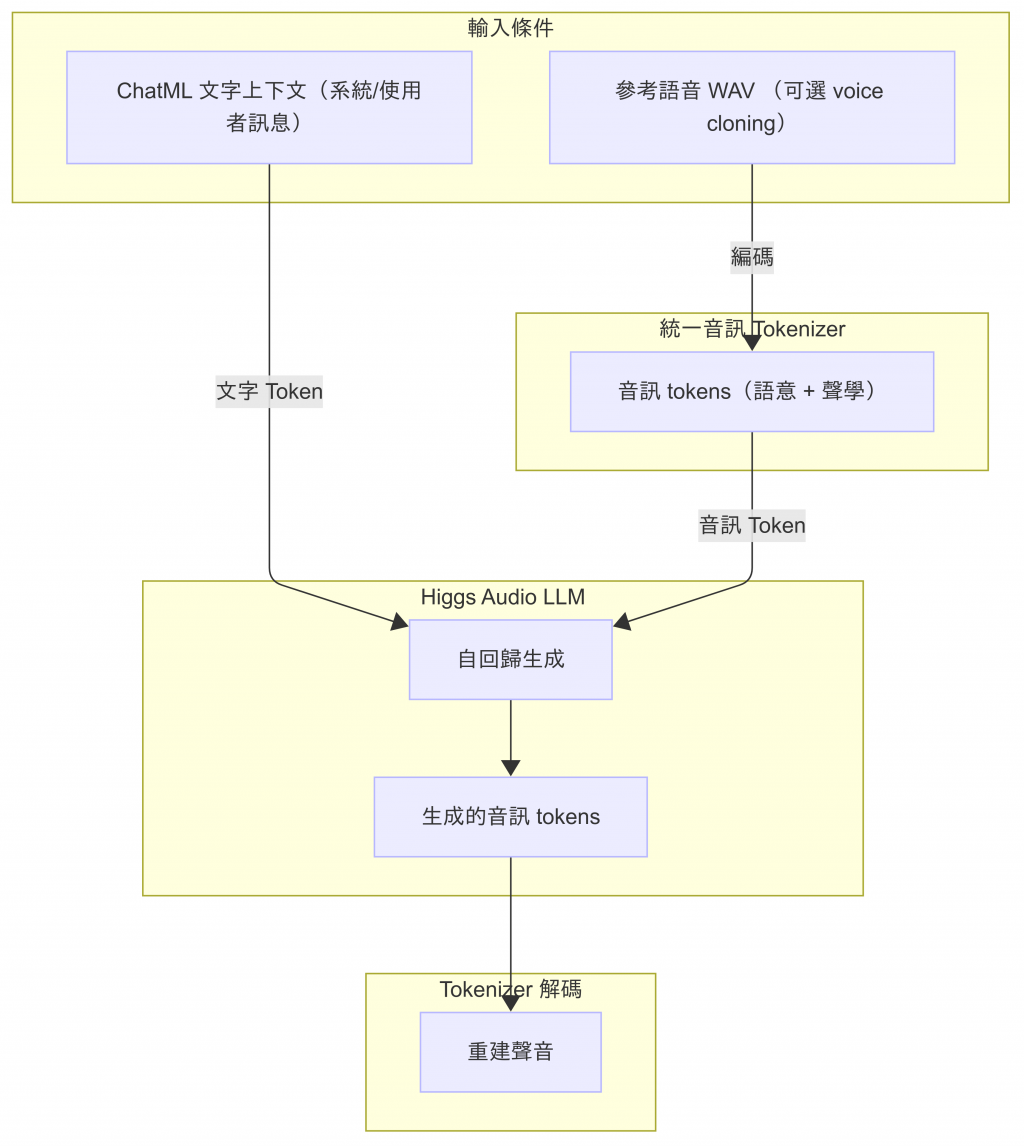
補充說明
上面提到的
vector_quantize_pytorch、descript-audio-codec只是幫助理解的工具例子,Higgs-Audio v2 實際上是 Boson AI 自己重新設計和訓練過的模型
vector_quantize_pytorch、descript-audio-codec 等),幫助理解「連續 離散 → 再生成」的流程
